

Geometry Meets Attention: Understanding SVDA from the Ground Up
Based on our newly (2025) published IEEE Access paper:
Geometry Meets Attention: Interpretable Transformers via SVD Inspiration
Self-attention is the engine behind modern Transformers, but standard dot-product attention is a black box. Why does a model attend to certain tokens? Can we understand what dimensions matter most—and why? This is where SVDA—SVD-inspired Attention—steps in. It introduces geometric structure and interpretability into attention, inspired by one of the most powerful matrix tools in linear algebra: the Singular Value Decomposition.
The Heart of SVDA: Spectrally Modulated Attention
Let’s start with the mathematical core. In SVDA, attention is not just about raw dot products. Instead, we modulate similarity between queries (



Here,

in which a matrix 
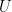

Why Normalize Queries and Keys?
Normalization ensures that attention reflects pure angular similarity—in other words, directional alignment. This removes the impact of vector magnitude and lets us interpret 

This gives our attention mechanism a geometric backbone. But why stop there?
Learning a Spectrum: Enter
Instead of treating all feature dimensions equally, we want the model to learn which directions matter. That’s where the diagonal spectrum 
Each 

This gives the model fine-grained control: it can boost important semantic axes and suppress noisy ones—like shining a spotlight on meaningful directions.
Making Geometry Stick: Soft Orthonormality
To maintain clean semantics, we softly regularize 


This encourages the columns of these matrices to represent independent, non-redundant features. Without this constraint, attention may become tangled and hard to interpret.
The total training loss becomes:

where 
Interpretability Indicators: Looking Inside the Model
SVDA introduces a set of structural indicators to peek into what’s going on inside each attention head:
- Spectral Entropy: Measures how focused or diffuse the learned spectral energy distribution is.


- Effective Rank: Approximates the number of meaningful directions used in attention, based on entropy.

- Selectivity Index: Indicates how concentrated attention is across tokens—lower means sharper focus.

- Spectral Sparsity: Measures the proportion of latent dimensions effectively suppressed (near-zero energy).

- Angular Alignment: Captures how closely queries align with keys in direction (cosine similarity).

- Perturbation Robustness: Quantifies sensitivity of the attention map to small input perturbations.

Together, these form a toolkit for analyzing attention not by speculation—but by structure.
What Does It All Give Us?
SVDA makes attention interpretable in a principled way:
- We know which semantic directions are used
- We can diagnose compression potential
- We gain robustness indicators—without modifying the rest of the model
In our experiments across time series, language, and vision, SVDA preserved performance while providing measurable structural insight. This includes dropping entropy (i.e., fewer spectral modes dominate), increasing sparsity (suggesting learned pruning), and stable angular alignment trends per modality.
Theoretical Backbone: Why SVDA Works
The interpretability of SVDA is not just empirical—it has a solid theoretical foundation. In the Appendix of our paper, we formalize what SVDA optimizes and how it converges. At the core is a set of theorems that analyze the behavior of the spectrum
- Theorem (Entropy Convergence): Under mild assumptions, the learned spectrum
- Observation (Directional Specialization): When
- Interpretability Metrics: The entropy, sparsity, and rank of
These results justify using indicators like 


So, SVDA is not just a more explainable variant, it’s one with structure that can be measured and trusted.
Beyond the Paper
SVDA is not just a theoretical curiosity. It opens doors to:
- Designing low-rank or compressed attention modules
- Visualizing how attention evolves over time
- Embedding structured priors into transformer heads
All with little computational overhead and full architectural compatibility.
If you’re working in explainable AI, structured modeling, or simply want to build Transformers you can reason about—SVDA might be your next tool.
Deeper insight
Read the full paper: IEEE Access

